What is Data Cleaning? How to Improve Data Quality
Master data cleaning techniques to ensure accurate, consistent, and reliable datasets.
 March 4, 2025
March 4, 2025 8 minute reading
8 minute reading
A key principle that data scientists and software engineers learn early is that “Garbage in equals garbage out.” This concept refers to the fact that computers can’t think — they can only operate on the data humans give them. If the data is faulty or of poor quality, the computer’s decisions will also be faulty.
Several ways exist for data to be faulty. The two most common ones are:
The data sources are of poor quality, such as when they suffer from data bias.
The dataset contains inconsistent fields, errors, or missing values, and needs to be cleaned.
In this tutorial, we’ll explain what data cleaning is, how it’s done, and what tools you can use to turn your source data into high-quality data.
What is data cleaning?
Data cleaning — sometimes called “data cleansing” — is the process of fixing errors in an underlying dataset so the data becomes consistent and useful. The errors might include missing, duplicate, irrelevant, inconsistent, or incorrectly formatted data.
Data cleaning consists of a workflow of both manual and automated actions. It’s impossible to completely automate data cleaning because so many types of data fields exist.
Instead, data scientists look over data sources and try to find common inconsistencies or errors. When they discover these, they can then write code in Python or another suitable data-cleaning tool to automate that step of the process.
Sometimes, people call data cleaning “data scrubbing.” In its strictest sense, data scrubbing refers to repairing storage on a hard drive, but you can also use it to refer to data cleaning.
Why is data cleaning important?
“Dirty data” can occur in many ways. Data scientists spend 80% of their time getting data ready so they can analyze it, which includes cleaning it.
Failing to clean dirty data can lead to algorithm failures and code errors. For example, if you’re running a personal finance application and want to calculate someone’s take-home pay, you’d expect the data about earnings to be in numbers, not words. If someone earned $100 in tips, you’d expect the number “100,” not “one hundred.”
You can’t type “one hundred” into a calculator, and the part of a computer that handles mathematical calculations can’t understand words either. Your entire app would crash.
You’d be amazed how similar errors occur in the wild. For example, the value “$100” isn’t technically a number. The dollar sign at the start of that figure is a non-numeric character. Humans know that the dollar symbol is irrelevant — but computers don’t.
When cleaning data, you’d either have to remove that dollar symbol from the data source or write code to account for it. Both are valid approaches, and both fall under the category of “data cleaning.”
Common data quality issues
Let’s look at some of the most common data integrity issues that come up during the data cleaning process:
Types of data (or “data types”)
In computer programming, all data has a type. A “numeric” data type isn’t the same as a “date” data type. An integer isn’t the same as a floating number, and computers use a separate part of the processor to handle both types of numbers. If you send a floating point number to a process that expects an integer, the process will crash.
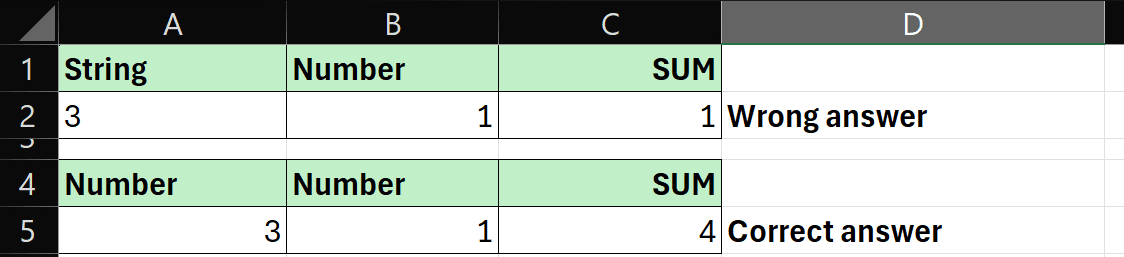
“Text” data is usually called a “String.” In the Excel sheet below, we wrote “3” as a String value in cell A2. When we sum this 3 with the 1 next to it, we get an incorrect answer (1). However, in the next row, we store “3” as a number and so receive the correct answer in column C. This is just one example of how faulty data leads to faulty conclusions.
Excel
Different language formats
Different regions and cultures have different ways of representing data.
For example, many European countries use the comma as a decimal separator and the period as a thousands separator. However, in English-speaking countries, we do the opposite. When paying someone, does ”$1,000” mean one dollar or a thousand dollars? In Germany, it would mean one dollar, and your employees might be immensely upset if they were expecting a thousand dollars instead.
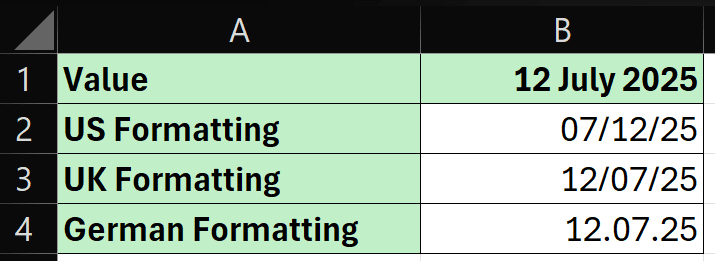
Dates are another common problem. America places the month before the day, whereas the British put the day first. If you run a wedding planning website and import the wedding date “12/07/2025,” does that mean the couple is getting married on July 12 or December 6?
You’d be amazed how often that simple error causes havoc.
Dozens of such formatting inconsistencies can exist across languages and cultures, as shown in the example below:
Excel
If your app needs to extract the day from the above data points, do you search for the first two digits before a forward slash or a period, or do you search for the next two digits following a slash?
Cleaning data from different regions is crucial for your code to operate smoothly with that data.
Find an Expert Data Cleaning for Hire
Data structure errors
Data comes in hundreds of different formats. One of the most common formats is comma-separated values (CSV).
However, even within CSV files, inconsistencies can exist. For example, in a CSV file, each data point is separated by a comma. However, if the data point itself has a comma (such as in the address “1 Acme Road, Notown, 5555, Nowhereland”), then it’s customary to enclose that data point in quotation marks, but not all systems follow that norm, leading to broken data.
In countries that use commas as decimal separators, it’s customary to use a semicolon as the separator in a CSV file instead of a comma. For example, data from two regions might look something like this:
US CSV File Row: “John, Doe, $1000.00, Transfer Successful”
Germany CSV File Row: “John; Doe; $1000,00; Transfer Successful”
The above rows represent the same record, but the German format uses a semicolon to separate the fields and a comma to indicate decimals. A computer would treat those rows as different data.
From a programming perspective, CSV files are unpleasant to deal with because they contain no metadata. For example, in more modern formats, you can specify what separator you’re using, the region, and other useful metadata that helps the underlying system process the file correctly.
The need for better data transmission formats led to attempts to standardize those formats and gave rise to more structured formats such as XML and JSON.
However, large swathes of the banking sector use legacy formats plus modern formats. Web hosts use log files, which is another format.
In short, it’s a mess, and data management platforms will often offer tools to automate the time-consuming process of merging all these different formats.
Lack of data validation
The best way to clean data is to prevent it from becoming dirty in the first place. That’s done with data validation.
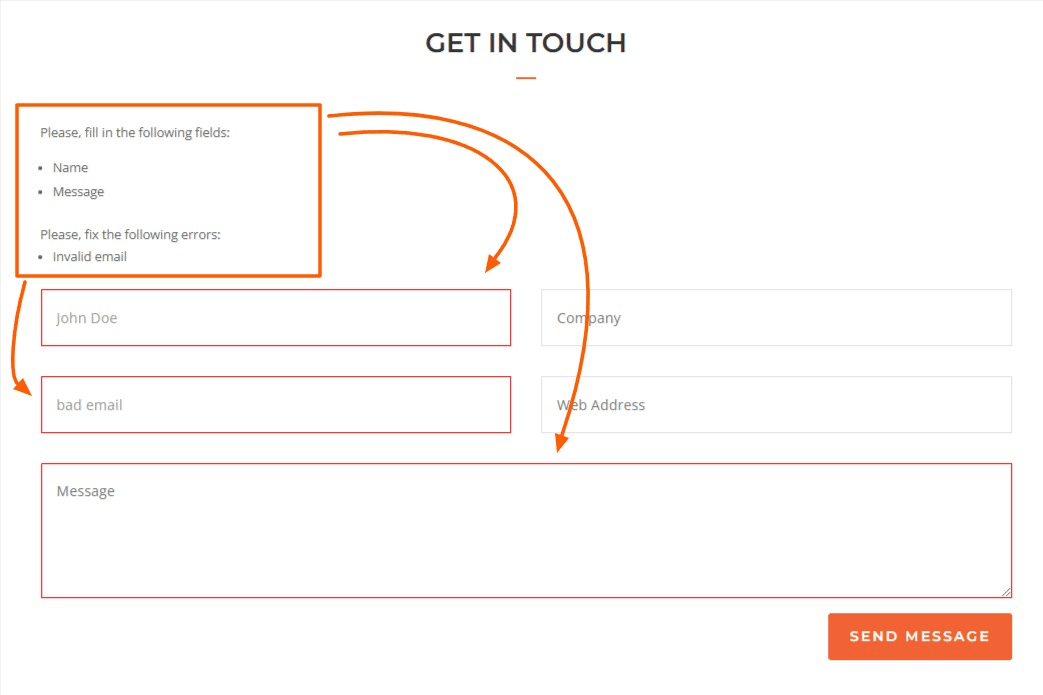
For example, if you have an input field for someone’s email, you can include data validation code to check that the person enters a valid email.
Data validation is also useful to prevent incomplete data, as shown below:
Contact form
Typos
One of the most common — and frustrating — errors in data science is typographical errors.
Various tools exist to reduce these errors during the data entry phase. For example, in some data entry cases, it’s possible to check an email address using specific APIs to determine if it exists.
Including a spellchecker in your app might also reduce errors.
However, typos are bound to exist, and you’ll need to build in checks during your data cleaning process to find them and handle them.
In some cases, it might be possible to add programmatic checks for typos, such as code to validate addresses. If the validation fails, the address might be incorrect.
Inaccurate data and poor data sources
In data science, it’s vital to ensure the quality of data is high. The data collection process must include finding reliable data sources that contain accurate data.
It’s far more time-consuming to clean data than to collect it accurately in the first place. One of the major challenges artificial intelligence companies are experiencing is a lack of reliable data. The major generative AI platforms today use internet data to train their models.
Unfortunately, internet data is rife with data biases, which have reduced the quality of these AI models’ output.
Duplicate records
Duplicate records reduce a dataset’s usability and can lead to various inconsistencies, such as inflated numbers, double-billed invoices, and generally flawed data analytics.
Most software programs take care to reduce duplicate records by having a unique identifier for each record. However, data can sometimes slide in despite these identifiers — this data is more challenging to discover and clean up.
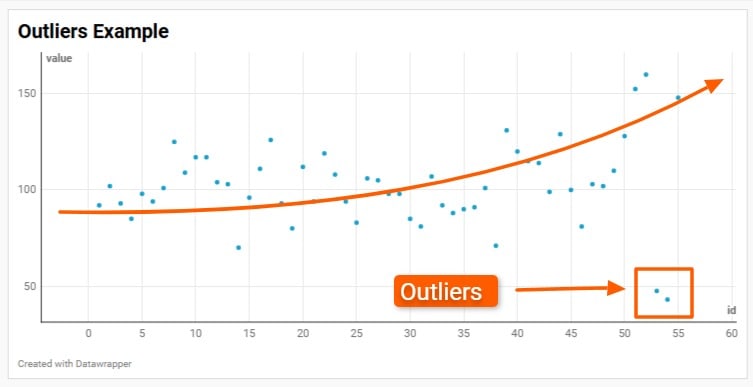
Outliers and anomalies
Outliers and anomalies are more significant in small datasets than in big data. In a small dataset, any extreme outlier could significantly sway a trend.
Using a standard deviation formula is a good way to spot outliers and, if it makes sense, remove them from the dataset.
Datawrapper
4 ways to clean your data
You can clean your data in four easy ways:
Data profiling
The first step in cleaning data is to understand it. That requires profiling the data by examining and analyzing it.
Data profiling provides a high-level view of the data and what needs to be done with it. After that, you can work out the manual and automated steps to clean the data.
Find a data engineer for hire
Data transformation
Data cleaning is a subset of the greater topic called Data Transformation.
Data comes in many different formats and from various data sources. Data transformation is the step of combining those sources and standardizing the data before using it.
Data transformation is essential for data cleaning because it defines what is “good” data and what is “bad” data.
“Good” data is data in the format that your tool expects it.
Hiring a data expert
The problem with erroneous data is there are endless ways data can be wrong but only one way it can be right. This makes data cleaning as much an art as a science.
The more data processing experience you have, the more you develop a sense of how data might be wrong in a data source.
That’s why it’s a good idea to hire a professional data cleaner to help you get your data into the right shape for business decision-making or data visualizations.
If you feel confident you can clean the data yourself but only need a few guidelines, then Fiverr’s data science consulting or data processing consulting services might be a good choice for you.
Tools for cleaning data
Data cleaning requires a combination of manual and automated tasks. The following tools help you automate the procedure more easily:
DataCleaner
DataCleaner is an open-source data profiling engine that helps you understand the quality of your data. To use it, you must install the Java Runtime environment.
DataCleaner
The tool has promising features but is somewhat neglected and lacks the user-friendliness of other tools. However, if you’re experienced in data cleaning, it has various built-in functions that can speed up the process of transforming and cleaning your data.
DataCleaner lets you connect to various cloud services.
Tableau Prep
Tableau Prep is a professional tool by Tableau, a data visualization company that’s part of Salesforce.
Tableau Prep has a slick user interface and is suitable for both beginners and advanced users.
Tableau
Microsoft Excel
Microsoft Excel is one of the most powerful data-cleaning tools around and will serve well enough for most small business use cases.
Not only does Excel offer powerful formulas for manipulating data, but you can also use its built-in programming language to perform sophisticated actions on the data.
Excel also lets you pull data directly from multiple data sources, such as SQL Server, Oracle, PostgreSQL, and Salesforce.
For everyday business use, Excel might be the only tool you need. You can then use the same workbook for creating visualizations to help you in business decision-making.
If you don’t know the syntax for Excel’s formulas, you can use the Formulas tab in the Ribbon to find the right formula to help you clean the data.
Microsoft Excel
Excel also has a built-in deduplication feature. You simply select the rows you want to process, then choose the columns to remove duplicates from, and Excel takes care of the rest.
If you need help with Excel processing, reach out to Fiverr for data processing services who works with Excel to help you.
Find data analytics services
Python with Pandas
Python Pandas is a code library specifically designed for working with data. Pandas lets you work with significantly larger datasets than Excel.
If you don’t know Python programming, you can get help from Fiverr’s expert software development services.
Hire a data cleaning expert on Fiverr today
As you’ve probably recognized, data cleaning is a practice requiring many skills, not only data science. You might need Excel skills, experience with Tableau, or direct programming skills.
Whether you’re looking for Python programmers or data engineering services, Fiverr has experts to help you.
Finding talent on Fiver is easy. Just sign up for a free Fiverr account and start searching for the right freelancer today.
Data cleaning FAQs
What is meant by data cleaning?
Data cleaning is the process of correcting data so it’s consistent and free of errors. Data cleaning is important to ensure that any machine learning done is based on accurate data.
What are the best methods for data cleaning?
Data cleaning requires a mix of manual and automated methods. The high-level process consists of first establishing what errors the data might have, then working out ways to automate cleaning any of that data.
Is data cleaning done in ETL?
Combining data from numerous sources into a single data warehouse is called “Extract, Transform, and Load” (ETL). Data cleaning typically occurs during the “Transform” step of this procedure.
How do you do data cleaning in Excel?
Excel is one of the most powerful tools for data cleaning. You can clean data in Excel using its built-in formulas or through its powerful programming language called VBA — Visual Basic for Applications.
Related Guides






About Author
R. Paulo Delgado Tech & Business Writer
R. Paulo Delgado is a tech and business freelance writer with nearly 17 years of software development experience under his belt, including WordPress programming. He is also a crypto journalist for Moneyweb, and proudly a member of Fiverr's Pro Seller program — hand-vetted professionals, verified by Fiverr for quality and service.
